Documentation Index
Fetch the complete documentation index at: https://parabola.io/docs/llms.txt
Use this file to discover all available pages before exploring further.
Input/output
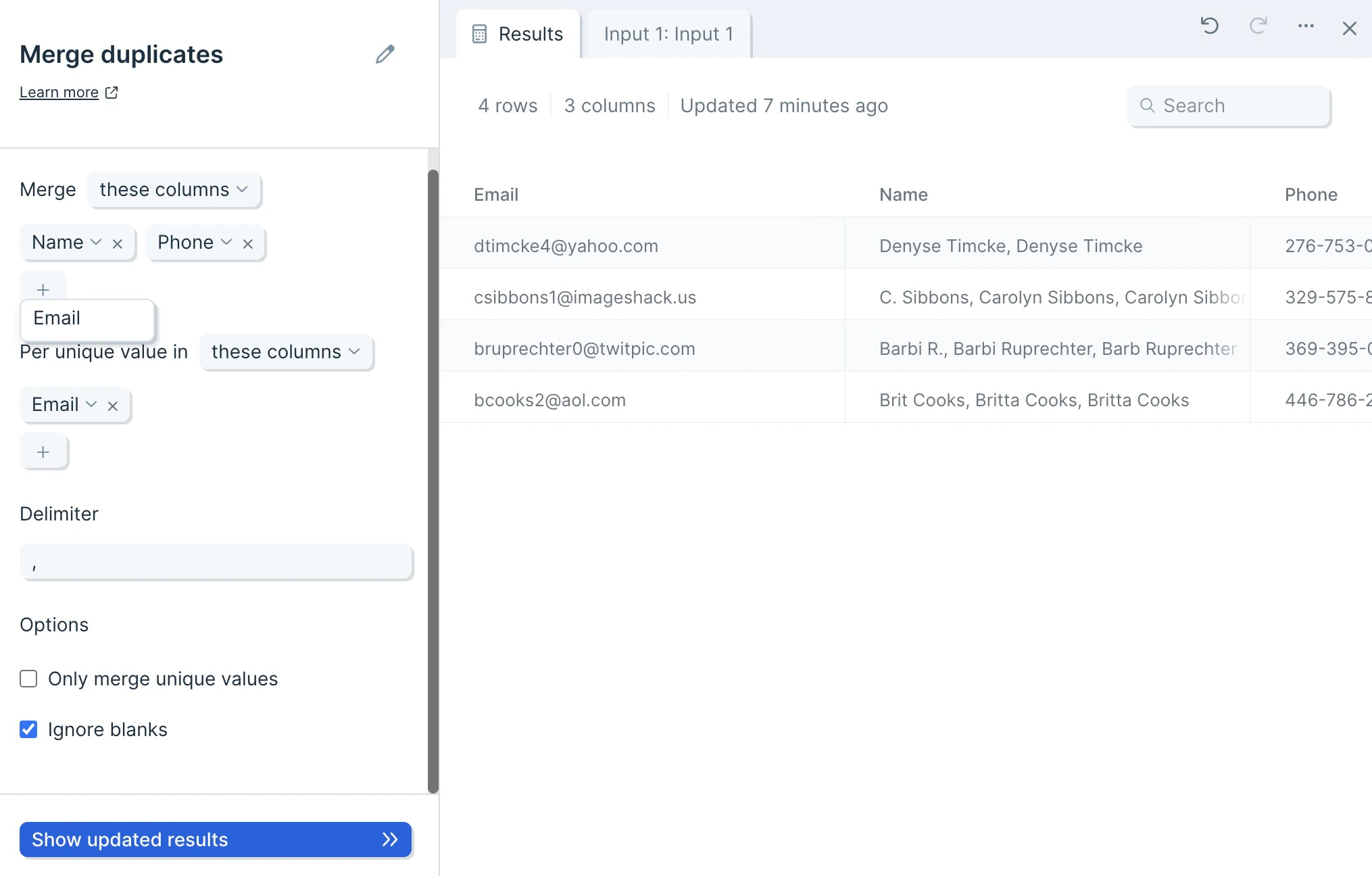
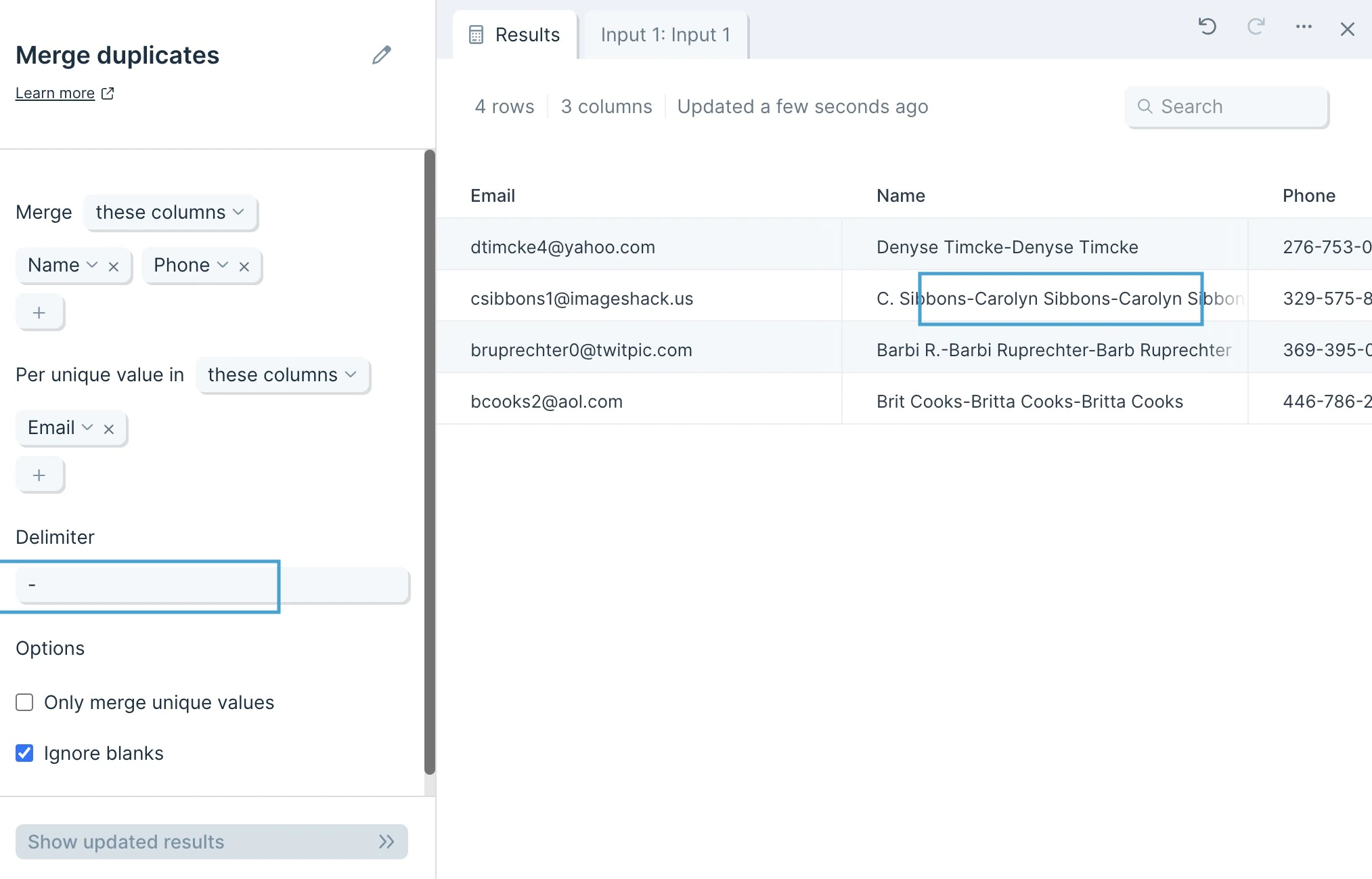
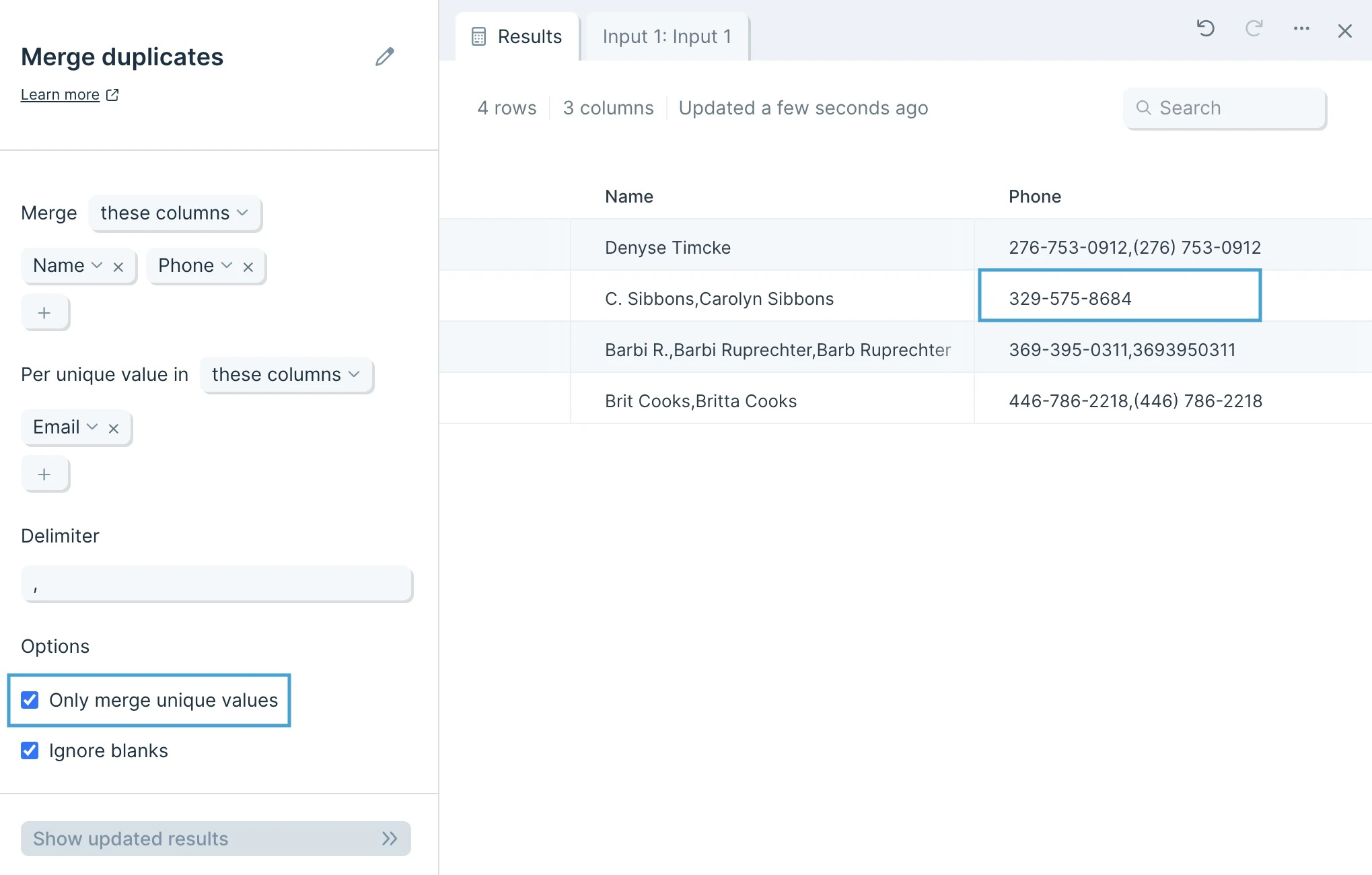
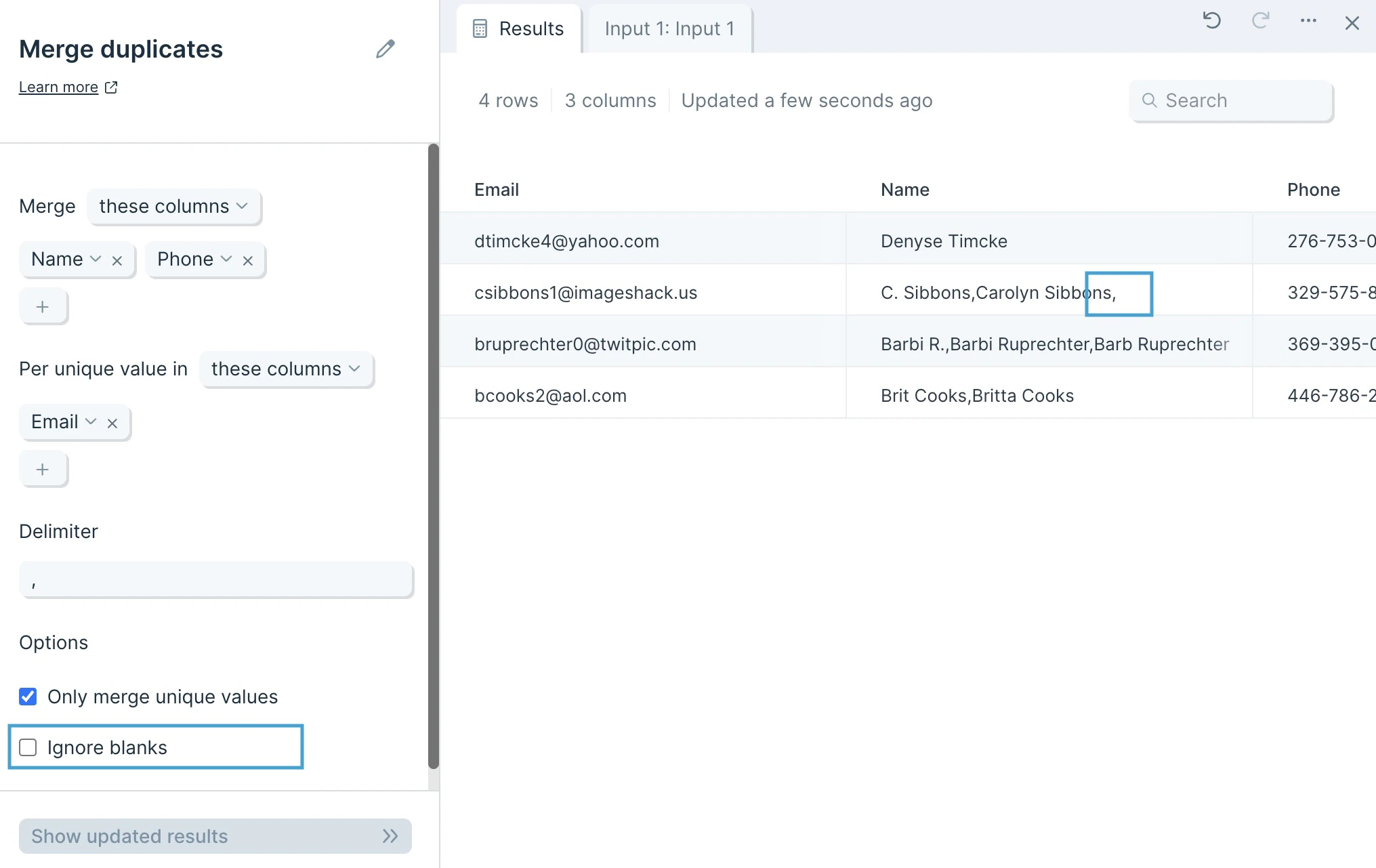
The data we’ll input into this step has an identifier type to deduplicate and its corresponding columns of data.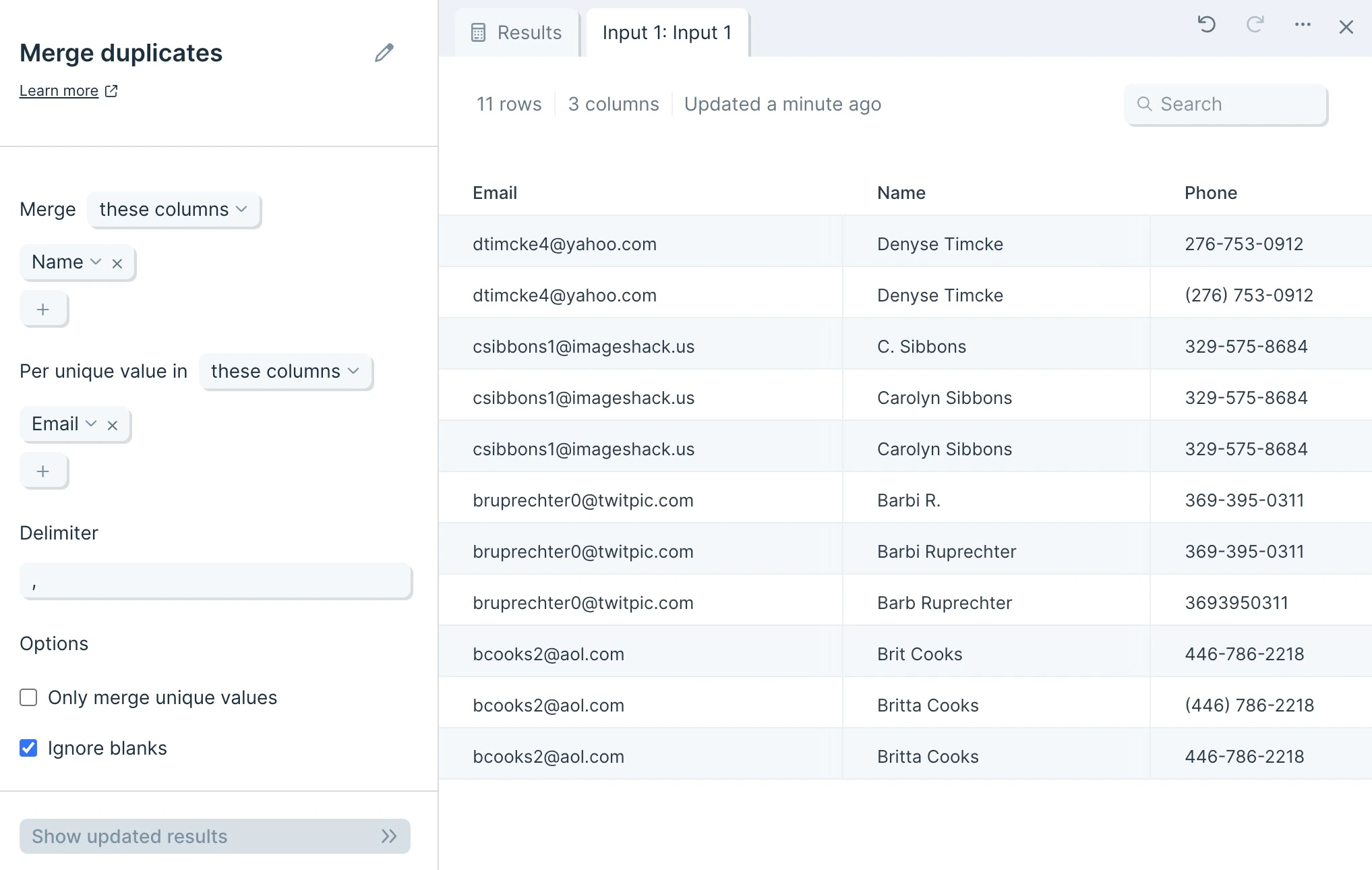
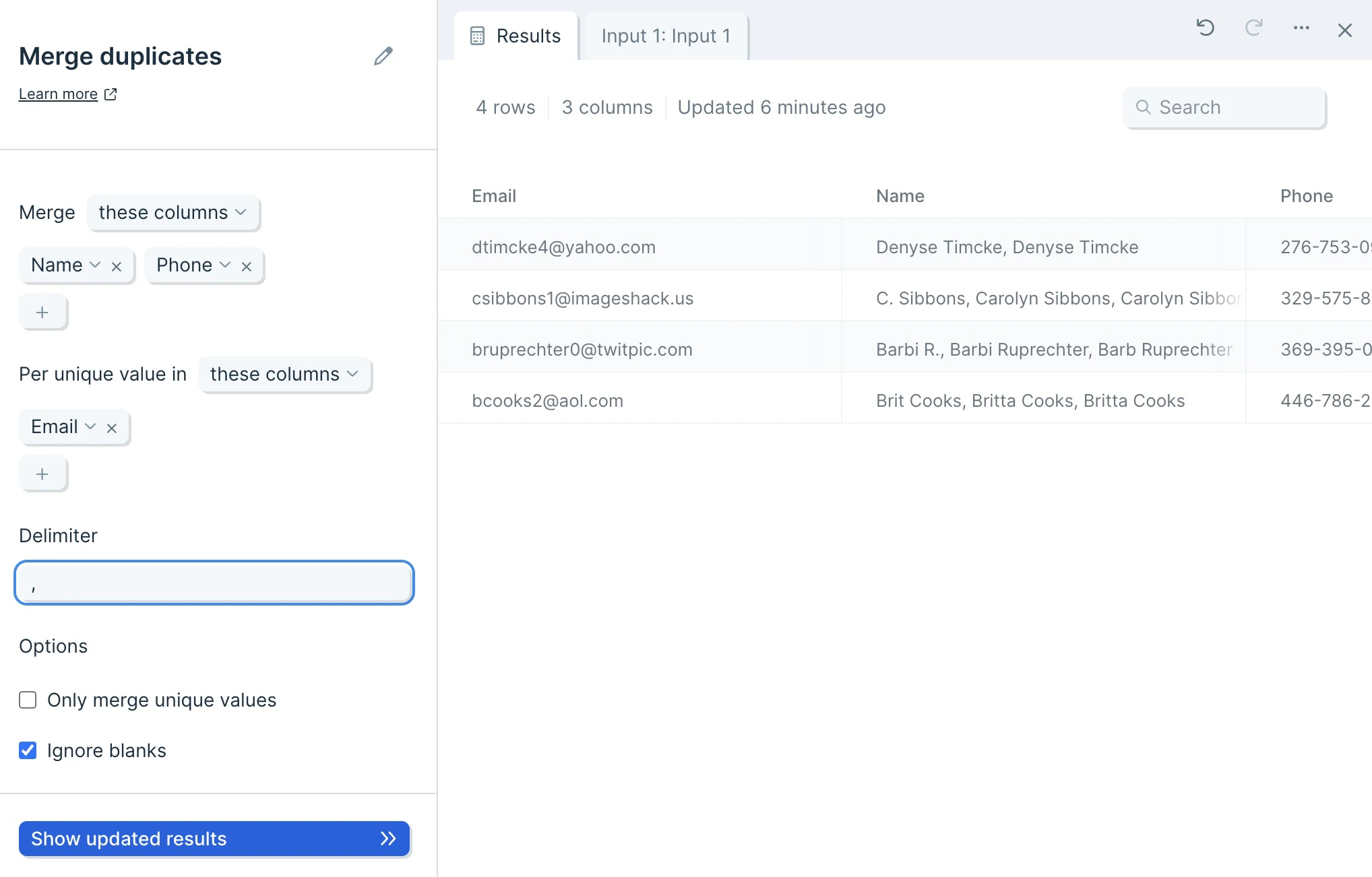
Default settings
By default, Parabola will map your first column to the unique value selector, and your second column to your Merge selector.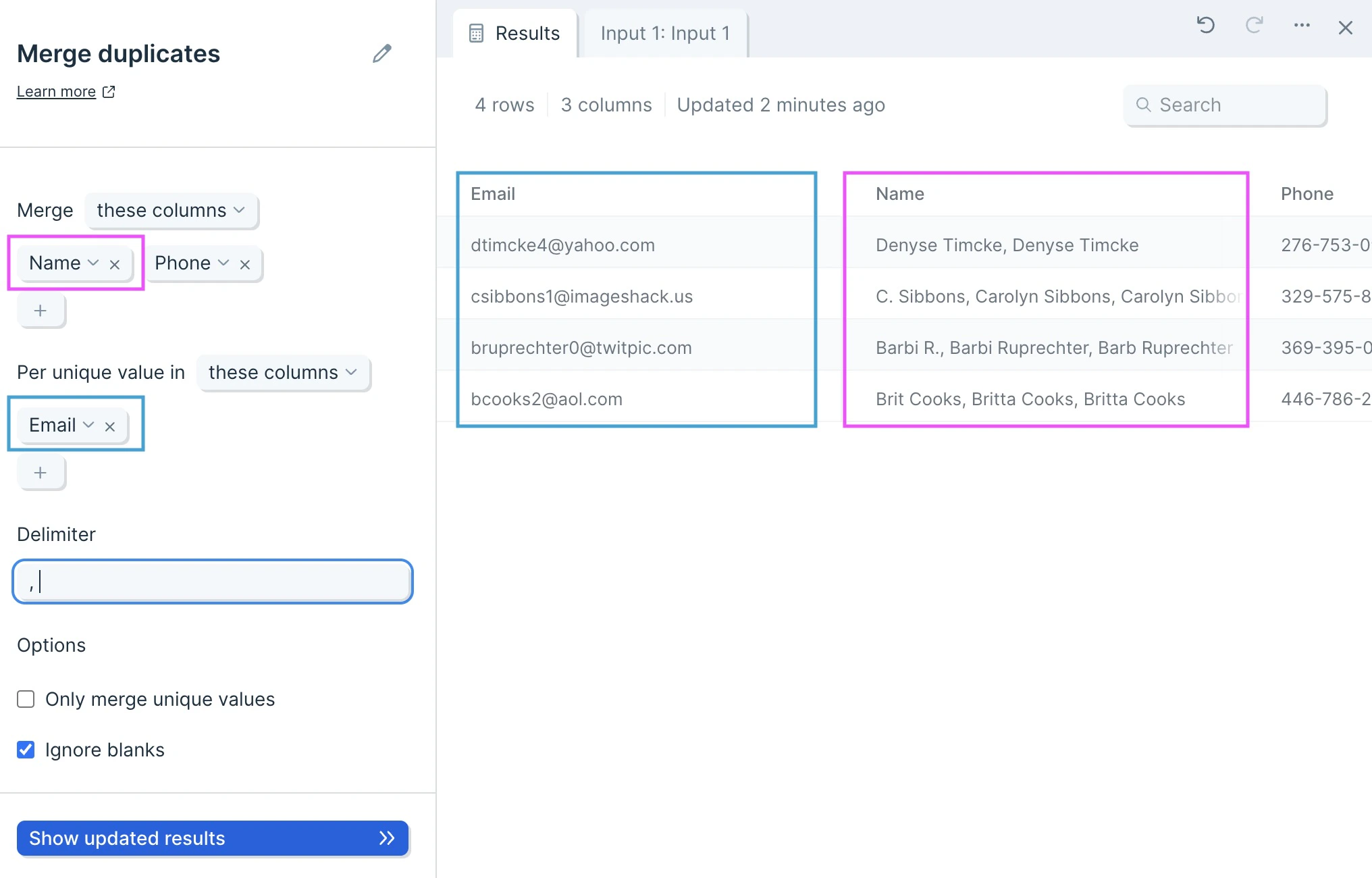
Custom settings
First, decide whether you want to include or exclude columns, by selecting these columns or all columns except.
Related steps
- Remove duplicate — drop duplicate rows entirely instead of merging their values.
- Sum by group — total numeric columns by a grouping key.
- Combine columns — concatenate columns within a single row.
- Split column — reverse a merge by splitting delimited values back apart.
- Pivot columns — pivot duplicate row values into columns instead.