Watch this Parabola University video to see the Remove duplicates step in action.Documentation Index
Fetch the complete documentation index at: https://parabola.io/docs/llms.txt
Use this file to discover all available pages before exploring further.
Input/output
Our input data has 100 rows with these 4 columns: “Webinar ID”, “Registrant name”, “Registration date” and “Registration time”.
Custom settings
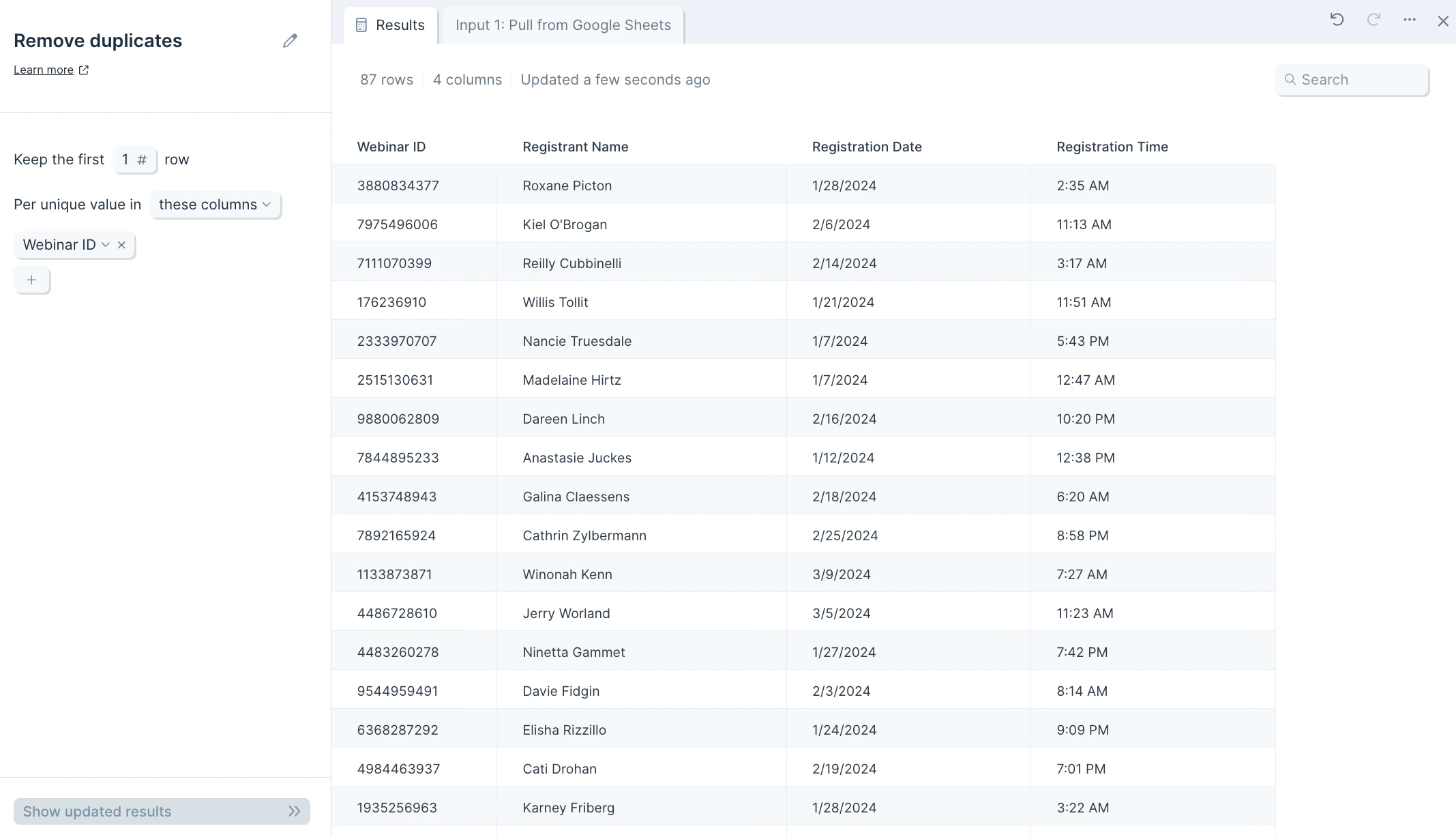
When you connect data into the Remove duplicates step, you’ll see a notification at the top of the step configuration that says, Per unique value in these columns: select from menu. First, select which column to look for duplicates. Clicking into the select from menu dropdown will expand a columns list to choose from.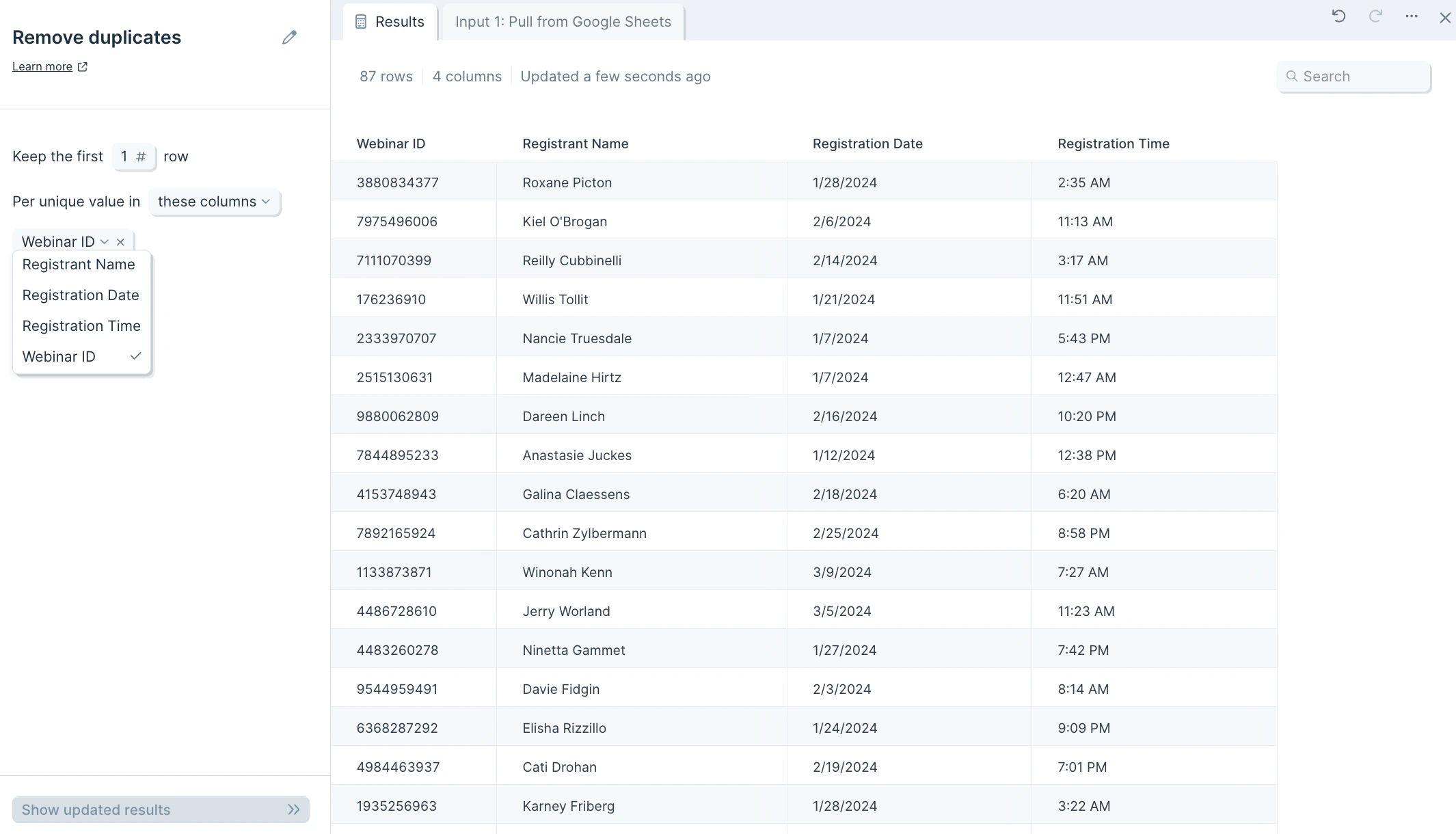
Helpful tips
- If you want to dedupe based on data existing across two or more columns, use a Combine columns step before the Remove duplicates step. This creates a column that has the values across your columns. You can then select that newly created column in your Remove duplicates step.
Related steps
- Merge duplicate — combine duplicate row values instead of dropping them.
- Combine columns — build a composite key when deduping on multiple fields.
- Sort rows — control which duplicate gets kept by sorting first.
- Filter rows — apply additional rules after duplicates are removed.
- Find overlap — compare two datasets for shared or unique rows.